
RFP template: Choosing AI technology for enterprise customer service
An excel sheet containing 100+ detailed evaluation questions across seven categories in scoring-ready format you can send directly to vendors.
Learn More

In the past few months, we’ve seen a rapid increase in the use of generative AI . Its application is vast — it can generate novel images, assist in coding, and transform your customer service strategy .
Although generative AI has quickly become a household name, you might still wonder exactly what it is and how it works . To sum it up briefly, generative AI refers to the ability to generate natural language using Large Language Models (LLMs). These models are trained on a large quantity of text from different sources (web pages, forums, etc.) and easily generate natural language in a conversational way.
LLMs are making an impact in a variety of fields, but they are especially powerful for customer service. With LLMs powering AI-first customer service, people are able to interact intelligently with automation — answering customers’ questions in natural language — to help them self-serve, take action, and have their inquiries resolved quickly.
At Ada, we’ve also discovered that it gives customer service employees more opportunity too — bot managers can move away from controlled dialogue flows and evolve their careers to become AI specialists in charge of more strategic projects and implementations.
That said, there are still challenges — especially when building a chatbot for customer service that will provide high quality conversations and resolutions. It’s not as easy as writing a prompt that tells the LLM to behave like a customer service agent.
The Machine Learning team at Ada has experienced some of these challenges firsthand. I’m going to walk you through them and give you an inside look at how we work to overcome them.
LLMs are trained on a large sum of data that cover a broad range of topics, but they are only trained up to a certain date. While this is common knowledge to your average ML scientist, it’s likely that a business onboarding AI to the customer service strategy for the first time wouldn’t be aware of this.
To give a couple relevant examples, at the time of writing this, OpenAI’s GPT-4 model was trained on data up to September 2021, and Anthropic’s Claude was trained on data up to December 2022.
In theory, building a chatbot for customer service could be as simple as drafting a prompt asking an LLM to behave as a customer service agent. The problem we face here is pretty straight forward: If I’m asking a question about something that happened yesterday, and the LLM has only been trained up to December of last year, the LLM will likely not have an accurate answer for me. It also means the AI might not have the available knowledge to answer very specific and technical questions.
One advantage of using LLMs for customer service is that it’s a constrained problem, meaning that it’s answering a limited set of questions. And it is possible to provide more up-to-date information — and mitigate LLMs hallucinations at the same time — by using a technique called Retrieval Augmented Generation (RAG).
RAG is a powerful technique — it requires no additional training of the LLM. You simply need to pass the additional information you want the LLM to use along with the instructions in the LLM prompt. Because LLMs have a lot of knowledge baked in, using RAG to prime the LLM on what is being discussed is critical to the accuracy and relevance of responses.

It’s well-known that LLMs are prone to hallucinations. They are capable of making up fake information and have a tendency to fill in the gaps — and they do this in a strikingly confident and assertive manner. It’s possible to limit LLM hallucinations by selecting and providing relevant knowledge, but unfortunately this isn’t enough. Additional precautions need to be taken.
While some hallucinations could be more or less forgivable, we want safe, accurate and relevant answers when dealing with customer service. For example, when asking a chatbot about a return policy, we want to make sure the accurate information is delivered to the user. Here’s how to ensure this happens.
You can add guardrails to prevent LLMs from generating wrong and potentially harmful answers. At Ada, we use three filters that ensure we deliver safe, accurate, and relevant answers.
First is a safety filter to ensure answers are free from toxic language and ideology or straight gibberish. Once we’ve validated that the generated answer is safe, we check the information contained in the generated response for accuracy and ensure it’s up-to-date with the company’s policies. Finally, we ensure the generated answer is relevant and is going to help the customer solve their problem.
While LLMs provide natural dialogue flows and can answer customer questions, they are not able to come up with an out-of-the-box solution and take creative steps to solve a customer issue. For example, an LLM by itself cannot check the balance on my account or update my email address in my account.
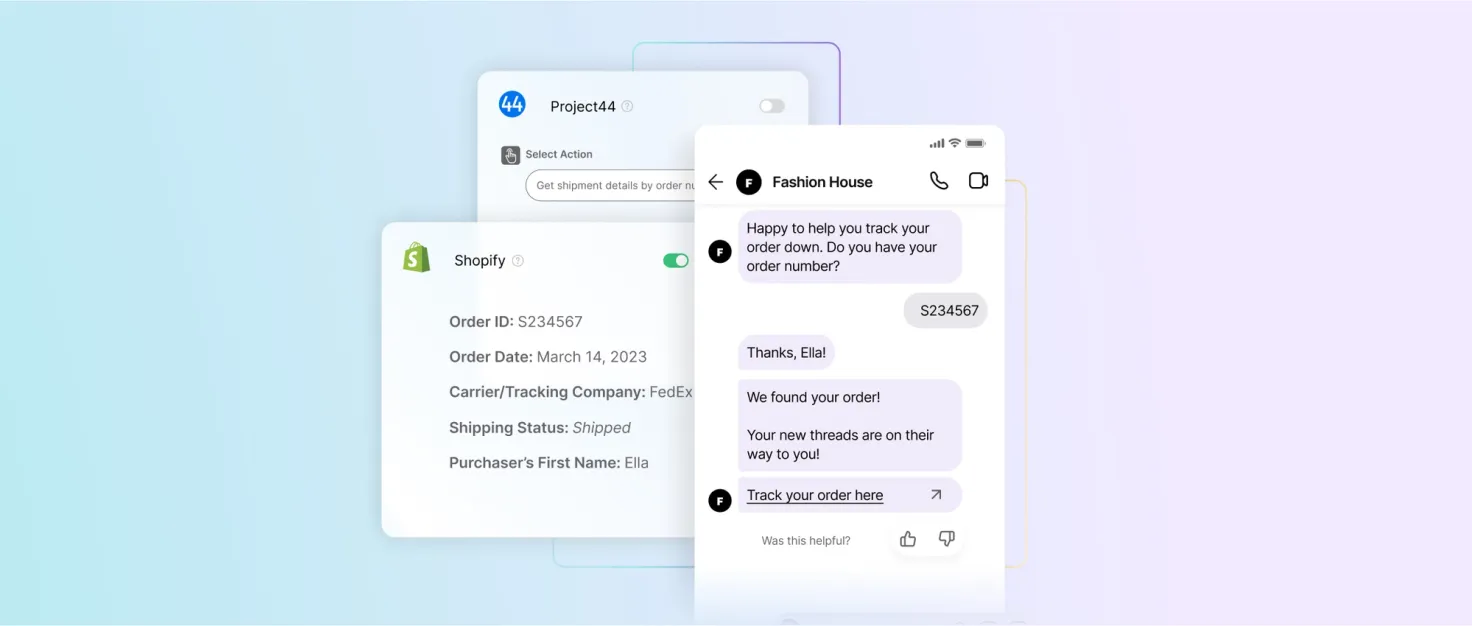
There are limits to the solutions LLMs can propose, and this can restrict interactions with customers. For example, let’s say I made an order that was recently shipped and I want to track my package. If I just provide my order number to an LLM, it wouldn’t have the ability to access my order and check where my package is.
Fortunately at Ada, we enable chatbots to resolve customer inquiries that necessitate taking actions by integrating and using information from clients APIs. To do so, we provide the LLM with all the actions that are available from client APIs. The LLM will then be able to reason and select the appropriate action. Now, if I provide my order number to the chatbot, it will be able to track my order and return its status.
A major challenge when using LLMs is finding an appropriate way to evaluate their performance. Because the input to an LLM is natural language, it’s easy to set up something that works in some cases. However, LLMs are non-deterministic — asking the same question several times can potentially return different answers. This makes it very challenging to evaluate LLM performance and find metrics to reflect how well a model is performing in general or for a specific task like customer service.
When using deterministic conversation flows, we would know which user’s question triggered a specific chatbot answer. This would allow us to easily evaluate our models and shed light to problems that could exist in our system. With LLMs, this isn’t possible anymore. We have to change our perspective on what a successful answer is and how to measure that.
AI chatbots in customer service are only as good as the number of inquiries they can automatically resolve. At Ada, we have several ways to assess the impact of changes we introduce to our AI system. One core process is measuring Automated Resolutions (AR) — a successful fully automated conversation between a customer service automation and a customer.
Automated Resolutions are conversations between a customer and a company that are safe, accurate, relevant, and don’t involve a human.
Every hour, we sample engaged conversations from 24 hours prior. An LLM assesses each conversation transcript for the above criteria, and then labels them either Resolved or Unresolved. To meet the criteria for AR, the resolution must be:
It's no secret to us (and hopefully not to you) that AI and automation will transform customer service in the coming years. This will allow human customer service agents to be elevated to more strategic and important roles in the company, but it also means there’s a growing need to reliably measure the efficacy of AI in customer service. We’re up to the challenge. Are you?
Practical guides to evolve your team, strategy, and tech stack for an AI-first world.
Get the toolkit

